
DeepSeek, Mistral ve LLaMA gibi Büyük Dil Modelleri (LLM’ler) araştırma laboratuvarlarından gerçek dünyadaki uygulamalara geçti — sohbet botları, arama motorları, kişisel asistanlar ve kurumsal yapay zekâ araçlarını güçlendiriyor.
Ancak bu modelleri üretime almak tak-çalıştır bir işlem değildir. Özellikle LLM dağıtım stratejileri etrafında kritik mimari kararlar içerir.
Bu yazıda en yaygın LLM dağıtım yöntemlerini keşfedecek, yan yana karşılaştıracak ve görseller, gerçek kullanım senaryoları ve performans verileriyle hangisini ne zaman kullanmanız gerektiğine yardımcı olacağız.
Yapay zekâ ile oluşturuldu
Bir dağıtım yöntemi seçmeden önce şu soruyu yanıtlayın:
Artıları:
Eksileri:
En uygunu : MVP’ler, hızlı prototipler, sınırlı altyapıya sahip girişimler veya barındırma derdi olmadan en iyi modelleri kullanmanız gereken durumlar.
Modeli kendi GPU sunucunuzda veya yerel makinenizde çalıştırırsınız.
Artıları:
Eksileri:
Hugging Face tarafından geliştirilmiştir
REST API üzerinden çalışır (Docker tabanlı)
Quantize modelleri ve GPU ivmesini destekler

Yapay zekâ ile oluşturuldu
Her dağıtım yöntemiyle hızlıca başlamanıza yardımcı olacak gerçek dünya komutları:
Ek kurulum gerektirmeden saniyeler içinde quantize bir Mistral modelini yerelde çalıştırır.
vLLM ile yüksek performanslı, OpenAI tarzı bir API uç noktası başlatır (OPT 1.3B). /chat/completions ile uyumludur.
Hugging Face’in TGI’si ile Mistral-7B-Instruct modelini servis etmeye hazır tam işlevli bir REST API oluşturur.
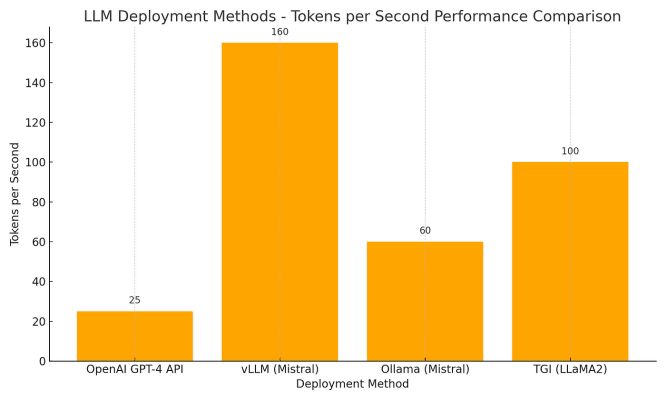
Farklı platformlar için ortalama token üretim hızı örneği:
🟢 vLLM aktarım hızında parlıyor 🟠 Ollama yerel kullanım için yeterince hızlı 🔵 OpenAI API ağ/API gecikmesi nedeniyle daha yavaştır ancak kullanım kolaylığı sunar
Yapay zekâ ile oluşturuldu
Bu modelleri verimli çalıştırmak için gereken yerel bellek (RAM):
Yoğun trafikli üretim sistemleri için kritiktir:
vLLM sektör seviyesinde ölçeklenebilirlik sunarken, Ollama kişisel uygulamalar veya düşük trafikli iç araçlar için idealdir.
LLM dağıtımında herkese uyan tek bir yaklaşım yok.
👉 Basit bir uygulama kuruyorsanız, bir API yeterli olabilir. 👉 Trafiği ölçekliyorsanız, vLLM size binlerce dolar tasarruf ettirebilir. 👉 Tam gizlilik veya çevrimdışı kullanım istiyorsanız, Ollama harika bir seçimdir.
Kullanım senaryonuzu bilin. Maliyeti kontrol edin. Performansı optimize edin.
Hangi dağıtım yöntemini kullandınız? Neler işe yaradı, neler yaramadı?
Yorumlara düşüncelerinizi veya sorularınızı bırakın — deneyiminizi duymak isteriz!
Medium sayfası için buraya tıklayın.